In a significant move toward solidifying the infrastructure for production-grade AI, the llm-d project is being contributed to the Cloud Native Computing Foundation (CNCF) as a Sandbox initiative.
This commitment, spearheaded by a multi-vendor coalition including CoreWeave, IBM Red Hat, Google, and NVIDIA, aims to establish an open standard for distributed inference. By integrating llm-d into the cloud native stack, the goal is to transform high-performance AI serving into a foundational capability, closing the gap that exists between initial AI experimentation and scalable, mission-critical deployment.
The industry is rapidly entering an agentic future where AI inferencing will power large numbers of enterprise agents, and according to an announcement from Red Hat SVP and AI CTO Brian Stevens, but he noted that “it will become critical that the cost and complexity of inferencing doesn’t outweigh the business value of the agents themselves. But inference can be incredibly expensive, consuming vast amounts of specialized accelerators, and at scale, costs can soar further. The advanced capabilities of llm-d directly address this, delivering against enterprise Service Level Objectives while maximizing infrastructure efficiency.”
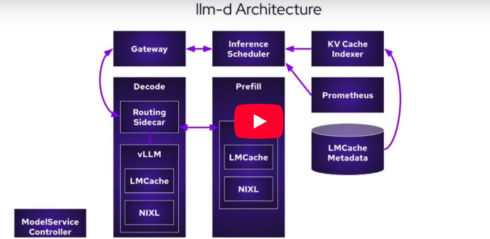
While organizations require the flexibility to deploy inference anywhere—on-premise, in the cloud, or at the edge—this portability hinges on an open source ecosystem. Standard Kubernetes orchestration was not designed to handle the demands of Large Language Model (LLM) inference. llm-d utilizes Kubernetes-native primitives, notably the Gateway API and LeaderWorkerSet (LWS), to turn complex distributed inference into a manageable, observable cloud-native workload, Stevens wrote.
A core component of llm-d is the Endpoint Picker (EPP), which provides programmable, inference-aware routing. The EPP implements the Kubernetes Gateway API Inference Extension (GAIE) and enables the system to make intelligent routing decisions based on the actual state of the serving engine, optimizing for metrics like Key Value cache hit rates and hardware accelerator efficiency. This capability is fundamental for maintaining consistent throughput while meeting strict service level objectives, the announcement said.
The project, Stevens wrote, enriches the CNCF ecosystem by ensuring inference is treated as a first-class citizen alongside traditional container applications. It works to complement existing components: KServe leverages llm-d for features like disaggregated serving and prefix caching, the Gateway API receives upstream alignment for AI-specific traffic management, and tools like Prometheus and Grafana gain specialized metrics such as time to first token (TTFT) for enterprise-grade observability. Since its launch in May 2025, llm-d has gained traction in enterprise AI and large-scale initiatives. Contributing llm-d to the CNCF ensures the project’s open roots continue to deepen, fostering a collaborative, future-ready foundation for open-source AI.