When it comes to telemetry data – meaning the logs, metrics, traces and other information engineers use to monitor applications, manage performance and troubleshoot outages– more is usually better. But there’s a big caveat: If you fail to manage telemetry data effectively, the data can quickly create more problems than it solves, leading to problems like higher storage costs, difficulty finding the right information when responding to failures and the risk of exposing sensitive information to unauthorized access.
That’s why telemetry pipelines have become an essential ingredient in modern application observability and performance management strategies, and a critical resource when deploying tools like Security Information and Event Management (SIEM) platforms.
That, at least, is a high-level overview of what telemetry pipelines do, and their importance from both a technical and a business perspective. For a deeper dive, keep reading as we draw on our collective experience in designing, implementing and managing telemetry pipelines to explain why they’re so valuable, and what to look for when building a telemetry pipeline tailored to your organization’s needs.
What are telemetry pipelines, and why do they matter?
Telemetry pipelines are a type of solution that collects, processes and routes telemetry data – which means logs, metrics, traces and any other kind of information that provides visibility into application performance.
Telemetry data has been important for decades, given the central role it plays in allowing organizations to monitor application performance, detect problems and troubleshoot them in ways that minimize the impact on users. But until relatively recently, few organizations had deliberate strategies in place for managing that data. Instead, they relied on ad hoc approaches for collecting data from the places where it originates and moving it to the tools they relied on to analyze it.
That approach worked well enough in most cases when the volume of logs, metrics and traces that a business managed was relatively low. But in today’s world of distributed software architectures, the amount of telemetry data that the typical organization must contend with has exploded. Instead of having to collect just one set of logs files and metrics for each application, as you would have done in the age of monolithic apps, it’s common today for a single application to consist of a dozen or more microservices, each of which generates its own logs and metrics. Couple that with the fact that today’s apps often run on distributed infrastructure that may consist of hundreds or thousands of individual servers, and it’s easy to see why there is so much more telemetry data to manage today.
To handle that volume efficiently, most organizations need more than an ad hoc solution for collecting, processing and routing data. They require a purpose-built solution that systematically pulls data from the various sources where it originates, normalizes and transforms it as necessary and delivers it to the places where it’s analyzed or stored. They need, in other words, a telemetry pipeline.
The benefits of telemetry pipelines
By bringing consistency and order to telemetry data management, telemetry pipelines produce a range of business benefits. The most important include:
- Cost reduction: Pipelines can help reduce the cost of processing and storing telemetry data through capabilities like deduplication, which removes redundant data, thereby reducing storage volumes and costs; and data minimization, which reduces the amount of data ingested into analytics tools, resulting in lower costs to operate tools that are priced based on total data ingested.
- Data privacy and security: Telemetry data may contain sensitive information, such as personally identifiable information (PII) stored in log files. By providing capabilities like encryption for data in motion, telemetry pipelines help protect sensitive data and meet compliance obligations.
- Enhanced application performance: The faster and more reliably you can move telemetry data from its place of origin to the place where you analyze it, the better you’ll be at detecting and fixing software performance issues before they lead to failure.
- Centralized control and visibility: A telemetry pipeline gives you a consolidated view of all of your telemetry data. This means you’ll always know which data sources are available, how you’re using them and what you could do to make your telemetry process even more efficient.
- Operational flexibility: Once you build a telemetry pipeline, you can easily swap data sources and destinations in and out as required. This means you can connect deploy apps or analytics tools at will, without having to implement custom telemetry management processes for each one.
- Freedom from lock-in: Along similar lines, telemetry pipelines help ensure that businesses can easily migrate to different analytics or application performance management tooling without being tied into a particular vendor’s stack due to the challenge of having to update complex telemetry data management processes.
Telemetry pipeline features: Basic vs. advanced
To deliver the benefits we just discussed, every telemetry pipeline solution worthy of the name should provide a core set of features, including:
- Collection, meaning the ability to pull data from the disparate places where it originates.
- Processing, which transforms data in various ways so that it is ideally suited for use by analytics or application performance management tools.
- Routing, or the delivery of processed data to the various tools that an organization uses to analyze or interpret it. Routing can also deliver data to long-term storage repositories if the organization needs to retain the data.
These, however, are the bare minimum features that telemetry pipelines must support. To achieve optimal pipeline efficiency and flexibility, organizations should seek out several key additional capabilities.
The OpenTelemetry Project
OpenTelemetry (or OTel for short) is an open framework governed by the Cloud Native Computing Foundation that offers a standardized approach to collecting, processing and transmitting telemetry data.
OTel has become a virtually universal standard, with its tools experiencing more than 30 million downloads each month. which means that as long as your pipeline supports OTel, you’ll be able to use the pipeline to connect almost any data source to any data analytics or management tool.
Supporting OTel ensures that a telemetry pipeline will work with any OTel-compatible data source or tool. However, to maximize the flexibility of your pipeline and minimize the risk of vendor lock-in, you can take openness a step further by building a pipeline that includes minimal proprietary components.
When your pipeline software is open – meaning it’s based on transparently, standardized components – you don’t have to worry about becoming locked into your pipeline software itself, or beholden to a particular vendor to support the tool you depend on to work with telemetry data.
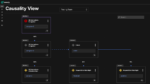
Processing previews allow you to predict how any data processing routines that you’ve configured within a pipeline will change your data. This is important because you don’t want to discover after the fact that you processed data in a way that made it unusable, or that introduced errors or formatting problems. With previews, you can take a more proactive approach to data management and get ahead of data issues in real time.
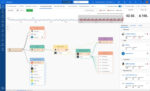
In addition to viewing data as it flows through individual pipelines, the ability to summarize all data within your pipeline helps you track how much data you’re processing and what you’re doing with it. In turn, these insights allow you to identify long-term trends involving your telemetry data. They can also help to track telemetry costs and find opportunities to streamline data workflows.
How to build a telemetry pipeline
Once you’ve decided what you need your telemetry pipeline to do and found software that does it, you need to implement the pipeline itself – which can be a challenging task, given the complexity of modern pipelines and telemetry data.
We won’t walk through every step of the implementation process here, since the specifics vary depending on which telemetry pipeline software you’re using. What we would like to mention, however, are implementation and operational challenges that teams sometimes overlook, such as:
- Agent migration: You may already have software monitoring agents in place that are collecting data from applications or services. Rather than reconfiguring these agents, you’ll ideally be able to migrate them into your pipeline, which saves time and reduces the effort required to implement a new pipeline.
- Pipeline observability: You’ll need a way to monitor and observe your pipeline itself to detect potential performance issues or errors.
- Pipeline scalability: It’s a safe bet that the volume of telemetry data that businesses must contend with will only increase in coming years. For that reason, it’s important to ensure that your pipeline can scale up to accommodate ever-larger volumes of data, as well as an increase in the number of data sources and tools it supports.
The bottom line
For many businesses, traditional approaches to managing telemetry data no longer suffice. They’re too slow, costly and challenging to scale.
The solution is to take a deliberate, consistent approach to telemetry data, processing and delivery by building a pipeline to ensure that every data source reaches its intended destination ready to support its intended use case. When you do this, you’ve set your organization up for long-term success in the era of increasingly large and complex telemetry data sets.
You may also like…